It’s the end of December and it seems that yet another year has gone by, so I figured that I’d write an EOY update to summarize my main work at Igalia as part of our Chromium team, as my humble attempt to make up for the lack of posts in this blog during this year.
I did quit a few things this year, but for the purpose of this blog post I’ll focus on what I consider the most relevant ones: work on the Servicification and the Blink Onion Soup projects, the migration to the new Mojo APIs and the BrowserInterfaceBroker, as well as a summary of the conferences I attended, both as a regular attendee and a speaker.
But enough of an introduction, let’s dive now into the gory details…
Servicification: migration to the Identity service
 As explained in my previous post from January, I’ve started this year working on the Chromium Servicification (s13n) Project. More specifically, I joined my team mates in helping with the migration to the Identity service by updating consumers of several classes from the sign-in component to ensure they now use the new IdentityManager API instead of directly accessing those other lower level APIs.
As explained in my previous post from January, I’ve started this year working on the Chromium Servicification (s13n) Project. More specifically, I joined my team mates in helping with the migration to the Identity service by updating consumers of several classes from the sign-in component to ensure they now use the new IdentityManager API instead of directly accessing those other lower level APIs.
This was important because at some point the Identity Service will run in a separate process, and a precondition for that to happen is that all access to sign-in related functionality would have to go through the IdentityManager, so that other process can communicate with it directly via Mojo interfaces exposed by the Identity service.
I’ve already talked long enough in my previous post, so please take a look in there if you want to know more details on what that work was exactly about.
The Blink Onion Soup project
Interestingly enough, a bit after finishing up working on the Identity service, our team dived deep into helping with another Chromium project that shared at least one of the goals of the s13n project: to improve the health of Chromium’s massive codebase. The project is code-named Blink Onion Soup and its main goal is, as described in the original design document from 2015, to “simplify the codebase, empower developers to implement features that run faster, and remove hurdles for developers interfacing with the rest of the Chromium”. There’s also a nice slide deck from 2016’s BlinkOn 6 that explains the idea in a more visual way, if you’re interested.

“Layers”, by Robert Couse-Baker (CC BY 2.0)
In a nutshell, the main idea is to simplify the codebase by removing/reducing the several layers of located between Chromium and Blink that were necessary back in the day, before Blink was forked out of WebKit, to support different embedders with their particular needs (e.g. Epiphany, Chromium, Safari…). Those layers made sense back then but these days Blink’s only embedder is Chromium’s content module, which is the module that Chrome and other Chromium-based browsers embed to leverage Chromium’s implementation of the Web Platform, and also where the multi-process and sandboxing architecture is implemented.
And in order to implement the multi-process model, the content module is split in two main parts running in separate processes, which communicate among each other over IPC mechanisms: //content/browser, which represents the “browser process” that you embed in your application via the Content API, and //content/renderer, which represents the “renderer process” that internally runs the web engine’s logic, that is, Blink.
With this in mind, the initial version of the Blink Onion Soup project (aka “Onion Soup 1.0”) project was born about 4 years ago and the folks spearheading this proposal started working on a 3-way plan to implement their vision, which can be summarized as follows:
- Migrate usage of Chromium’s legacy IPC to the new IPC mechanism called Mojo.
- Move as much functionality as possible from
//content/renderer down into Blink itself.
- Slim down Blink’s public APIs by removing classes/enums unused outside of Blink.
Three clear steps, but definitely not easy ones as you can imagine. First of all, if we were to remove levels of indirection between //content/renderer and Blink as well as to slim down Blink’s public APIs as much as possible, a precondition for that would be to allow direct communication between the browser process and Blink itself, right?
In other words, if you need your browser process to communicate with Blink for some specific purpose (e.g. reacting in a visual way to a Push Notification), it would certainly be sub-optimal to have something like this:

…and yet that is what would happen if we kept using Chromium’s legacy IPC which, unlike Mojo, doesn’t allow us to communicate with Blink directly from //content/browser, meaning that we’d need to go first through //content/renderer and then navigate through different layers to move between there and Blink itself.
In contrast, using Mojo would allow us to have Blink implement those remote services internally and then publicly declare the relevant Mojo interfaces so that other processes can interact with them without going through extra layers. Thus, doing that kind of migration would ultimately allow us to end up with something like this:

…which looks nicer indeed, since now it is possible to communicate directly with Blink, where the remote service would be implemented (either in its core or in a module). Besides, it would no longer be necessary to consume Blink’s public API from //content/renderer, nor the other way around, enabling us to remove some code.
However, we can’t simply ignore some stuff that lives in //content/renderer implementing part of the original logic so, before we can get to the lovely simplification shown above, we would likely need to move some logic from //content/renderer right into Blink, which is what the second bullet point of the list above is about. Unfortunately, this is not always possible but, whenever it is an option, the job here would be to figure out what of that logic in //content/renderer is really needed and then figure out how to move it into Blink, likely removing some code along the way.
This particular step is what we commonly call “Onion Soup’ing //content/renderer/<feature>” (not entirely sure “Onion Soup” is a verb in English, though…) and this is for instance how things looked before (left) and after (right) Onion Souping a feature I worked on myself: Chromium’s implementation of the Push API:

Onion Soup’ing //content/renderer/push_messaging
Note how the whole design got quite simplified moving from the left to the right side? Well, that’s because some abstract classes declared in Blink’s public API and implemented in //content/renderer (e.g. WebPushProvider, WebPushMessagingClient) are no longer needed now that those implementations got moved into Blink (i.e. PushProvider and PushMessagingClient), meaning that we can now finally remove them.
Of course, there were also cases where we found some public APIs in Blink that were not used anywhere, as well as cases where they were only being used inside of Blink itself, perhaps because nobody noticed when that happened at some point in the past due to some other refactoring. In those cases the task was easier, as we would just remove them from the public API, if completely unused, or move them into Blink if still needed there, so that they are no longer exposed to a content module that no longer cares about that.
Now, trying to provide a high-level overview of what our team “Onion Soup’ed” this year, I think I can say with confidence that we migrated (or helped migrate) more than 10 different modules like the one I mentioned above, such as android/, appcache/, media/stream/, media/webrtc, push_messaging/ and webdatabase/, among others. You can see the full list with all the modules migrated during the lifetime of this project in the spreadsheet tracking the Onion Soup efforts.
In my particular case, I “Onion Soup’ed” the PushMessaging, WebDatabase and SurroundingText features, which was a fairly complete exercise as it involved working on all the 3 bullet points: migrating to Mojo, moving logic from //content/renderer to Blink and removing unused classes from Blink’s public API.
And as for slimming down Blink’s public API, I can tell that we helped get to a point where more than 125 classes/enums were removed from that Blink’s public APIs, simplifying and reducing the Chromium code- base along the way, as you can check in this other spreadsheet that tracked that particular piece of work.
But we’re not done yet! While overall progress for the Onion Soup 1.0 project is around 90% right now, there are still a few more modules that require “Onion Soup’ing”, among which we’ll be tackling media/ (already WIP) and accessibility/ (starting in 2020), so there’s quite some more work to be done on that regard.
Also, there is a newer design document for the so-called Onion Soup 2.0 project that contains some tasks that we have been already working on for a while, such as “Finish Onion Soup 1.0”, “Slim down Blink public APIs”, “Switch Mojo to new syntax” and “Convert legacy IPC in //content to Mojo”, so definitely not done yet. Good news here, though: some of those tasks are already quite advanced already, and in the particular case of the migration to the new Mojo syntax it’s nearly done by now, which is precisely what I’m talking about next…
Migration to the new Mojo APIs and the BrowserInterfaceBroker
Along with working on “Onion Soup’ing” some features, a big chunk of my time this year went also into this other task from the Onion Soup 2.0 project, where I was lucky enough again not to be alone, but accompanied by several of my team mates from Igalia‘s Chromium team.
This was a massive task where we worked hard to migrate all of Chromium’s codebase to the new Mojo APIs that were introduced a few months back, with the idea of getting Blink updated first and then having everything else migrated by the end of the year.

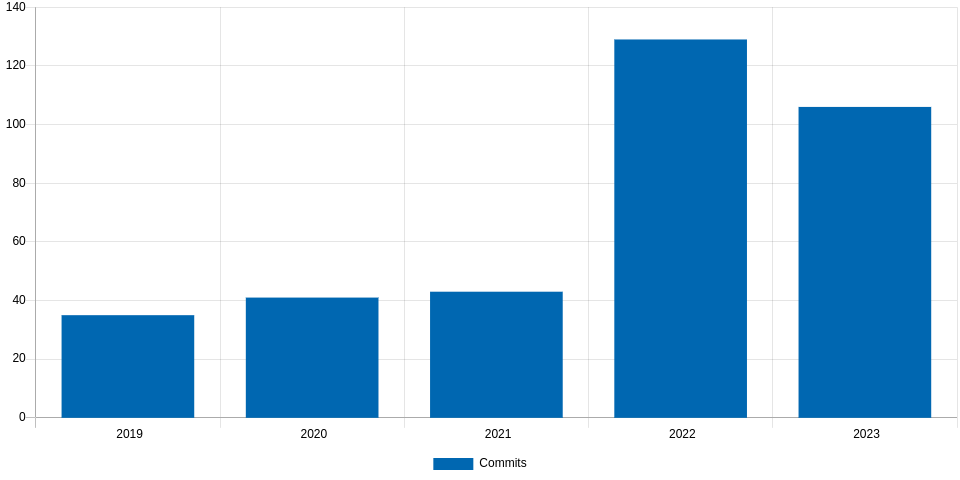
Progress of migrations to the new Mojo syntax: June 1st – Dec 23rd, 2019
But first things first: you might be wondering what was wrong with the “old” Mojo APIs since, after all, Mojo is the new thing we were migrating to from Chromium’s legacy API, right?
Well, as it turns out, the previous APIs had a few problems that were causing some confusion due to not providing the most intuitive type names (e.g. what is an InterfacePtrInfo anyway?), as well as being quite error-prone since the old types were not as strict as the new ones enforcing certain conditions that should not happen (e.g. trying to bind an already-bound endpoint shouldn’t be allowed). In the Mojo Bindings Conversion Cheatsheet you can find an exhaustive list of cases that needed to be considered, in case you want to know more details about these type of migrations.
Now, as a consequence of this additional complexity, the task wouldn’t be as simple as a “search & replace” operation because, while moving from old to new code, it would often be necessary to fix situations where the old code was working fine just because it was relying on some constraints not being checked. And if you top that up with the fact that there were, literally, thousands of lines in the Chromium codebase using the old types, then you’ll see why this was a massive task to take on.
Fortunately, after a few months of hard work done by our Chromium team, we can proudly say that we have nearly finished this task, which involved more than 1100 patches landed upstream after combining the patches that migrated the types inside Blink (see bug 978694) with those that tackled the rest of the Chromium repository (see bug 955171).
And by “nearly finished” I mean an overall progress of 99.21% according to the Migration to new mojo types spreadsheet where we track this effort, where Blink and //content have been fully migrated, and all the other directories, aggregated together, are at 98.64%, not bad!
On this regard, I’ve been also sending a bi-weekly status report mail to the chromium-mojo and platform-architecture-dev mailing lists for a while (see the latest report here), so make sure to subscribe there if you’re interested, even though those reports might not last much longer!
Now, back with our feet on the ground, the main roadblock at the moment preventing us from reaching 100% is //components/arc, whose migration needs to be agreed with the folks maintaining a copy of Chromium’s ARC mojo files for Android and ChromeOS. This is currently under discussion (see chromium-mojo ML and bug 1035484) and so I’m confident it will be something we’ll hopefully be able to achieve early next year.
Finally, and still related to this Mojo migrations, my colleague Shin and I took a “little detour” while working on this migration and focused for a while in the more specific task of migrating uses of Chromium’s InterfaceProvider to the new BrowserInterfaceBroker class. And while this was not a task as massive as the other migration, it was also very important because, besides fixing some problems inherent to the old InterfaceProvider API, it also blocked the migration to the new mojo types as InterfaceProvider did usually rely on the old types!

Architecture of the BrowserInterfaceBroker
Good news here as well, though: after having the two of us working on this task for a few weeks, we can proudly say that, today, we have finished all the 132 migrations that were needed and are now in the process of doing some after-the-job cleanup operations that will remove even more code from the repository! \o/
Attendance to conferences
This year was particularly busy for me in terms of conferences, as I did travel to a few events both as an attendee and a speaker. So, here’s a summary about that as well:
 As usual, I started the year attending one of my favourite conferences of the year by going to FOSDEM 2019 in Brussels. And even though I didn’t have any talk to present in there, I did enjoy my visit like every year I go there. Being able to meet so many people and being able to attend such an impressive amount of interesting talks over the weekend while having some beers and chocolate is always great!
As usual, I started the year attending one of my favourite conferences of the year by going to FOSDEM 2019 in Brussels. And even though I didn’t have any talk to present in there, I did enjoy my visit like every year I go there. Being able to meet so many people and being able to attend such an impressive amount of interesting talks over the weekend while having some beers and chocolate is always great!
Next stop was Toronto, Canada, where I attended BlinkOn 10 on April 9th & 10th. I was honoured to have a chance to present a summary of the contributions that Igalia made to the Chromium Open Source project in the 12 months before the event, which was a rewarding experience but also quite an intense one, because it was a lightning talk and I had to go through all the ~10 slides in a bit under 3 minutes! Slides are here and there is also a video of the talk, in case you want to check how crazy that was.
Took a bit of a rest from conferences over the summer and then attended, also as usual, the Web Engines Hackfest that we at Igalia have been organising every single year since 2009. Didn’t have a presentation this time, but still it was a blast to attend it once again as an Igalian and celebrate the hackfest’s 10th anniversary sharing knowledge and experiences with the people who attended this year’s edition.
 Finally, I attended two conferences in the Bay Area by mid November: first one was the Chrome Dev Summit 2019 in San Francisco on Nov 11-12, and the second one was BlinkOn 11 in Sunnyvale on Nov 14-15. It was my first time at the Chrome Dev Summit and I have to say I was fairly impressed by the event, how it was organised and the quality of the talks in there. It was also great for me, as a browsers developer, to see first hand what are the things web developers are more & less excited about, what’s coming next… and to get to meet people I would have never had a chance to meet in other events.
Finally, I attended two conferences in the Bay Area by mid November: first one was the Chrome Dev Summit 2019 in San Francisco on Nov 11-12, and the second one was BlinkOn 11 in Sunnyvale on Nov 14-15. It was my first time at the Chrome Dev Summit and I have to say I was fairly impressed by the event, how it was organised and the quality of the talks in there. It was also great for me, as a browsers developer, to see first hand what are the things web developers are more & less excited about, what’s coming next… and to get to meet people I would have never had a chance to meet in other events.
As for BlinkOn 11, I presented a 30 min talk about our work on the Onion Soup project, the Mojo migrations and improving Chromium’s code health in general, along with my colleague Antonio Gomes. It was basically a “extended” version of this post where we went not only through the tasks I was personally involved with, but also talked about other tasks that other members of our team worked on during this year, which include way many other things! Feel free to check out the slides here, as well as the video of the talk.
Wrapping Up
As you might have guessed, 2019 has been a pretty exciting and busy year for me work-wise, but the most interesting bit in my opinion is that what I mentioned here was just the tip of the iceberg… many other things happened in the personal side of things, starting with the fact that this was the year that we consolidated our return to Spain after 6 years living abroad, for instance.
Also, and getting back to work-related stuff here again, this year I also became accepted back at Igalia‘s Assembly after having re-joined this amazing company back in September 2018 after a 6-year “gap” living and working in the UK which, besides being something I was very excited and happy about, also brought some more responsibilities onto my plate, as it’s natural.
Last, I can’t finish this post without being explicitly grateful for all the people I got to interact with during this year, both at work and outside, which made my life easier and nicer at so many different levels. To all of you, cheers!
And to everyone else reading this… happy holidays and happy new year in advance!























 This is a fast recap on how Javascript heap works, you can skip it if you want
This is a fast recap on how Javascript heap works, you can skip it if you want



.jpg)





 .
.
 ), we are getting very good at catching deviations from how the SPARQL library should behave, and decently good at catching how it should not misbehave. Simply following W3C standards and recommendations pays off here too, since it settles the direction and resolves most matters about what the right behavior is.
), we are getting very good at catching deviations from how the SPARQL library should behave, and decently good at catching how it should not misbehave. Simply following W3C standards and recommendations pays off here too, since it settles the direction and resolves most matters about what the right behavior is.